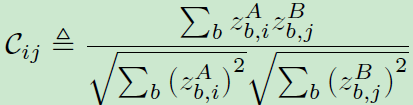Summary of Self-Supervised Learning

近期自监督学习论文总结。
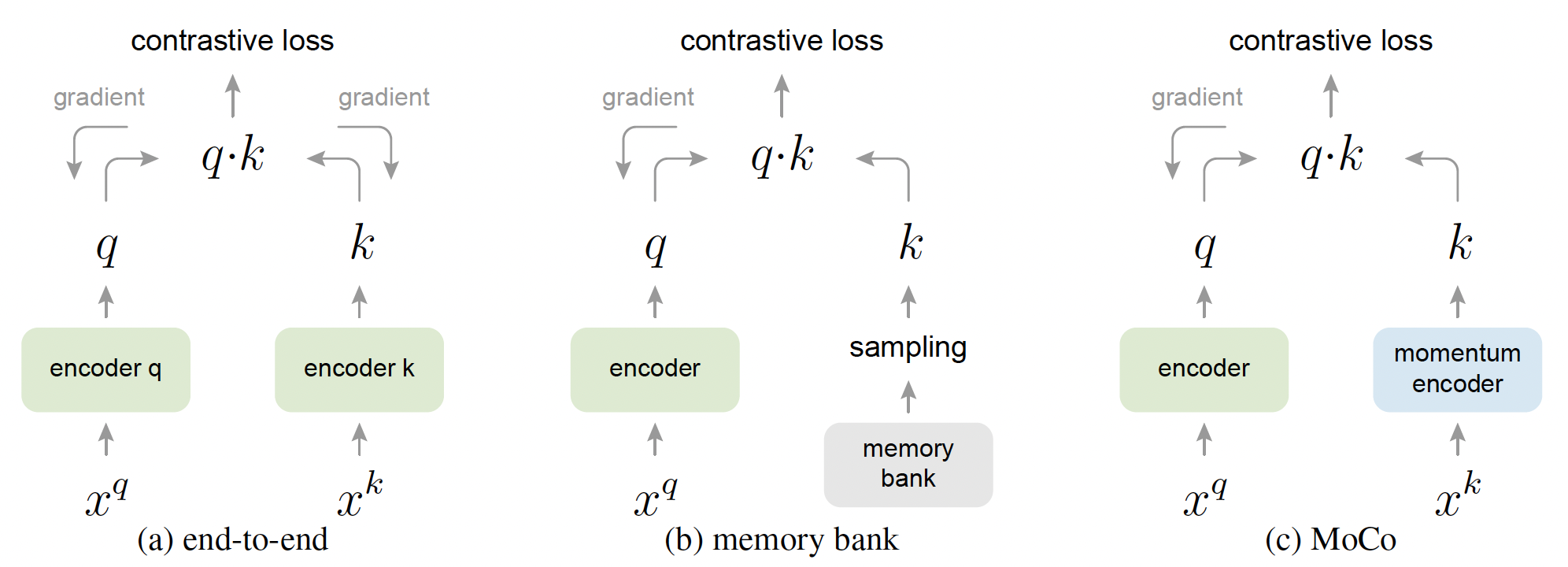
MoCo (Momentum Contrast for Unsupervised Visual Representation Learning, CVPR 2020)
Main idea
采用对比学习的方式学习图片表征,其核心是引入了具有队列的动态字典以及移动平均编码器。
- 它将dict size与mini-batch size解耦,将队列的大小作为超参数,而字典中的样本将被渐进替换。
- 此外,若直接把encoder q中的参数拷贝到encoder k中,快速变化的encoder将降低表示的一致性。因此,该工作采取了momentum update的方式,仅对encoder k进行少量更新。
Method
InFoNCE: 选取\([k_1,...,k_{K+1}]\), 含一个正样本\(k_+\), K个负样本\(k_i\) (其他随便信号)。
\[\mathscr{L}_q = - \rm{log} \frac{\rm{exp}(q \cdot k_{+} / \tau)}{\sum^{K}_{i=0} \exp (q \cdot k_i / \tau)}\]
Momentum Update
\[\theta_k \leftarrow m \theta_k + (1-m) \theta_q\]
BYOL (Bootstrap Your Own Latent A New Approach to Self-Supervised Learning, NIPS 2020)
Problem
现有的图片表示对比学习将同一图片的不同增强视图作为正样本,通过约束同一张图的不同形态之间的特征差异性来实现特征提取(一般通过数据增强实现)。 若仅有正样本,网络容易对所有输入都输出一个固定的值,这样特征差异性就是0,完美符合优化目标,但这不是我们想要的,即导致了Collapsing。
负样本对解决了训练崩塌的问题,但对数量要求较大,因为只有这样才能训练出足够强的特征提取能力,因此往往需要较大的batch size才能有较好的效果。
BYOL无负样本对,通过增加prediction和stop-gradient避免训练退化。
Motivation
作者首先展示了一个实验,一个网络参数随机初始化且固定的target network的top1准确率只有1.4%,而target network输出feature作为另一个叫online network的训练目标,等这个online network训练好之后,online network的top1准确率可以达到18.8%。
假如将target network替换为效果更好的网络参数(比如此时的online network),然后再迭代一次,也就是再训练一轮online network,去学习新的target network输出的feature,那效果应该是不断上升的,类似左右脚踩楼梯不断上升一样。
Method
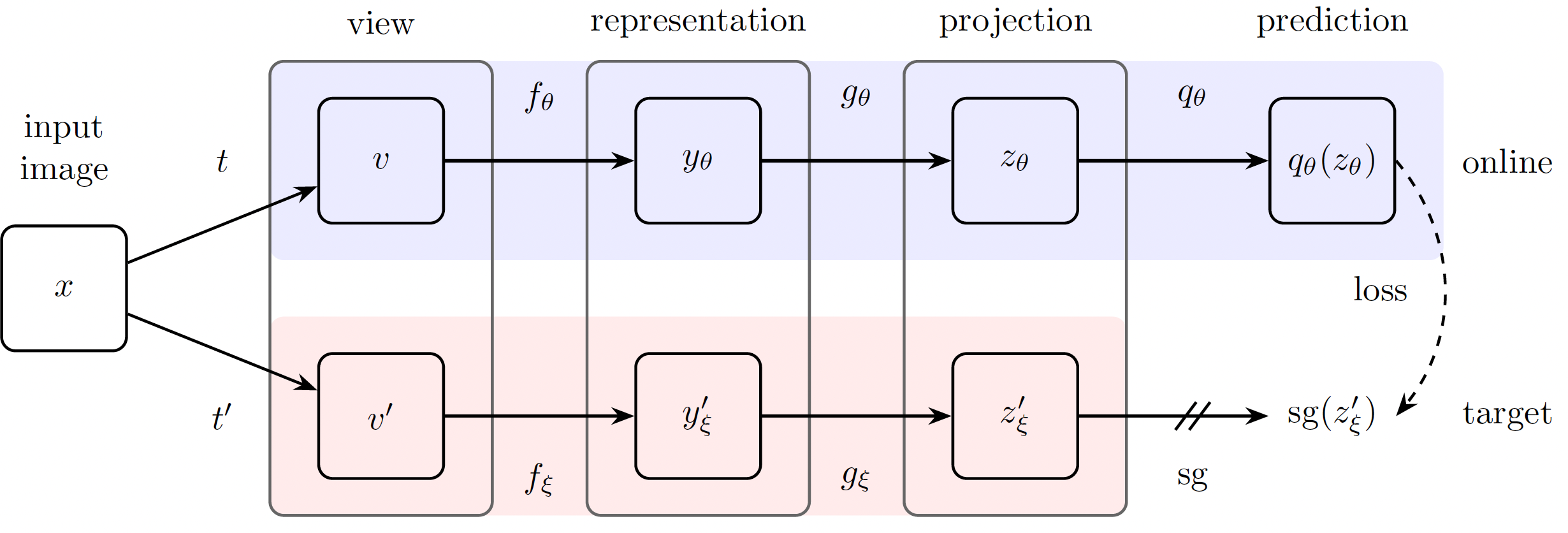
给定一个target network产生表示,用一个online network去预测target表示。若target与online同步更新,表现很差;若保持target不变,acc约18.8%。因此对target采用EMA(Exponential Moving Average)策略。
给定a set of weights of online network \(\theta\), a set of weight of target network \(\xi\), target decay rate \(\tau \in [0, 1]\),在训练之后进行以下更新:
\[\xi \leftarrow \tau \xi + (1- \tau) \theta\]
A set of images: \(\mathscr{D}\), an
image \(x~\mathscr{D}\) sampled
uniformly. 图像增强分布\(\mathscr{T}\)
and \(\mathscr{T}\).
\(v \triangleq t(x)\) and \(v' \triangleq t'(x)\): two
augmented views from \(x\).
\(y_{\theta} \triangleq f_{\theta}
(v)\): online network产生的表示
\(z_{\theta} \triangleq g_{\theta}
(y)\): projection
\(q_{\theta}(z_{\theta})\): prediction
of \(z'_{\xi}\)
分别对\(q_{\theta}(z_{\theta})\)和\(z'_{\xi}\)进行l2 归一化: \(\overline{q}_{\theta}(z_{\theta}) \triangleq
q_{\theta}(z_{\theta}) / || q_{\theta}(z_{\theta}) ||_2\), \(\overline{z}_{\theta} \triangleq z'_{\xi} /
||z'_{\xi}||_2\)
仅有online有predictor,两个branch之间是非对称的。
计算online的prediction和target的projection的MSE。
\[\mathscr{L}_{\theta , \xi} \triangleq || \overline{q_{\theta}} - \overline{z_{\xi}}' ||_2^2 = 2-2 \cdot \frac{<q_{\theta}, z'_{\xi}>}{||q_{\theta}||_2 \cdot ||z'_{\xi}||_2}\]
分别将\(v'\)输入online network、\(v\)输入target network计算\(\widetilde{\mathscr{L}}_{\theta , \xi}\),使得loss \(\mathscr{L}_{\theta , \xi}\)对称。
在每个训练步进行随机优化,针对\(\theta\)最小化\(\mathscr{L}^{BYOL}_{\theta, \xi}=\mathscr{L}_{\theta , \xi} + \widetilde{\mathscr{L}}_{\theta , \xi}\),而\(\xi\)则采取stop gradient策略。
\[\theta \leftarrow \rm{optimizer}(\theta, \nabla_{\theta} \mathscr{L}^{BYOL}_{\theta, \xi}, \eta) \xi \leftarrow \tau \xi + (1-\tau) \theta\] 其中\(\eta\)是个可学习参数。
ALBEF (Align before Fuse: Vision and Language Representation Learning with Momentum Distillation, NIPS 2021)
Main idea
大多数现有基于transformer作为多模编码器的工作共同建模visual tokens和word tokens,然而token之间是非对齐的,往往难以捕捉它们之间的交互。 本文提出, 1. 采用对比损失在cross-modal attention fusing之前对图像和文本进行对齐。 2. 为了应对噪声,提出momentum distillation,从momentum model所产生的伪标签中学习。
Method
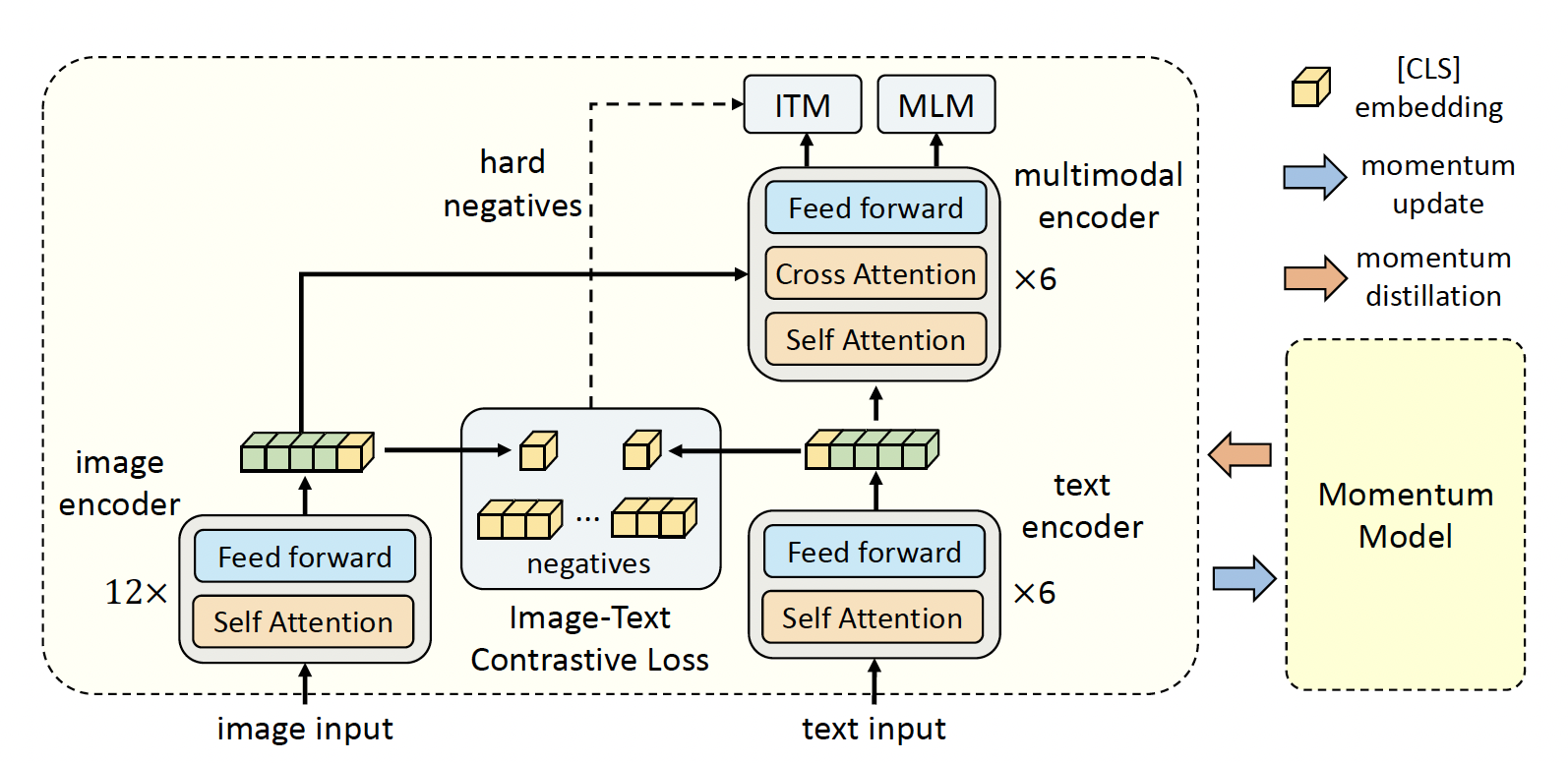
Pre-training Objectives
Image-Text Contrastive Learning
对比损失旨在在融合之前学习一个更好的单模表示。
需要学习一个similarity function \(s=g_v (\bf{v}_{cls})^{\top} g_w (\bf{w}_{cls})\)。受MoCo启发,维护了两个队列来保存由momentum unimodal encoders产生的最近的M个图片-文本表示。由momentum encoders所产生的归一化的特征表示为\(g'_v (\bf{v}_{cls}')\)和\(g'_w (\bf{w}_{cls}')\)。 我们定义\(s(I,T)=g_v (\bf{v}_{cls})^{\top}g_w' (\bf{w}_{cls}')\), \(s(T,I)=g_w (\bf{w}_{cls})^{\top}g_v' (\bf{v}_{cls}')\).
calculate the softmax-normalized image-to-text and text-to-image similarity as:
\[p^{i2t}_m (I)=\frac{\exp (s(I,T_m)/ \tau)}{\sum_{m=1}^{M} \exp (s(I, T_m)/\tau)}, p^{t2i}_m (T)=\frac{\exp (s(T,I_m)/ \tau)}{\sum_{m=1}^{M} \exp (s(T, I_m)/\tau)}\]
\(\tau\): learnable temperature parameter
\(\bf{y}^{i2t}(I)\) and \(\bf{y}^{t2i}(T)\): ground-truth one-hot similarity
对比损失被定义为\(\bf{p}\)和\(\bf{y}\)的交叉熵。
\[\mathscr{L}_{itc} = \frac{1}{2} \rm{E}_{(I,T) \backsim D} [\rm{H}(\bf{p}^{i2t}(I), \bf{y}^{i2t}(I)) + \rm{H}(\bf{p}^{t2i}(T), \bf{y}^{t2i}(T))]\]
Masked Language Modeling
利用图片和上下文文本信息去预测masked words。
\(\hat{T}\): masked text
\(\bf{p}^{msk} (I, \hat{T})\): model’s
predicted probability for a masked token.
MLM 最小化交叉熵:
\[\mathscr{L}_{mlm}=\rm{E}_{(I,\hat{T})\backsim D} \rm{H} (\bf{p}^{msk} (I, \hat{T}, \bf{y}^{msk})\] \(\bf{y}^{msk}\): one-hot vocabulary distribution,真实token的概率是1
Image-Text Matching
预测一组图文对为正(匹配)或负(不匹配)。仅采用[CLS] token的embedding。
\[\mathscr{L}_{itm} = \rm{E}_{(I,T) \backsim D} \rm{H}(\bf{p}^{itm}(I, T), \bf{y}^{itm})\]
\(\bf{y}^{itm}\): 2维one-hot ground-truth label向量表示
\[\mathscr{L} = \mathscr{L}_{itc} + \mathscr{L}_{mlm} + \mathscr{L}_{itm}\]
Momentum Distillation
正样本对往往弱相关,也会包含一些不相关的文本,或实体,而对于ITC学习来说,负文本可能也会包含一些匹配图片的信息。因此采用一个动量模型,它是一个exponential-moving-average versions of the unimodal and multimodal encoders。
For ITC,首先利用动量单模encoder产生的特征计算相似度:\(s'(I,T)=g_v'(\bf{v}_{cls}')^{\top} g_w'(\bf{w}_{cls}')\)以及\(s'(T,I)=g_w'(\bf{w}_{cls}')^{\top} g_v'(\bf{v}_{cls}')\)
之后,计算soft pseudo-targets\(\bf{q}^{i2t}\)和\(\bf{q}^{t2i}\),计算损失:
\[\mathscr{L}^{\rm{mod}}_{\rm{itc}} = (1-\alpha) \mathscr{L}_{itc} + \frac{\alpha}{2} \rm{E}_{(I,T) \backsim D} [\rm{KL}(\bf{p}^{i2t}(I), \bf{q}^{i2t}(I)) + \rm{KL}(\bf{p}^{t2i}(T), \bf{q}^{t2i}(T))]\]
For MLM, \(\bf{q}^{msk}(I,\hat{T})\)表示momentum model’s prediction probability for the masked token, 损失表示为:
\[\mathscr{L}^{\rm{mod}}_{\rm{mlm}} = (1-\alpha) \mathscr{L}_{mlm} + {\alpha} \rm{E}_{(I,\hat{T}) \backsim D} \rm{KL}(\bf{p}^{msk}(I,\hat{T}),\bf{q}^{msk}(I,\hat{T}))\]
Barlow Twins
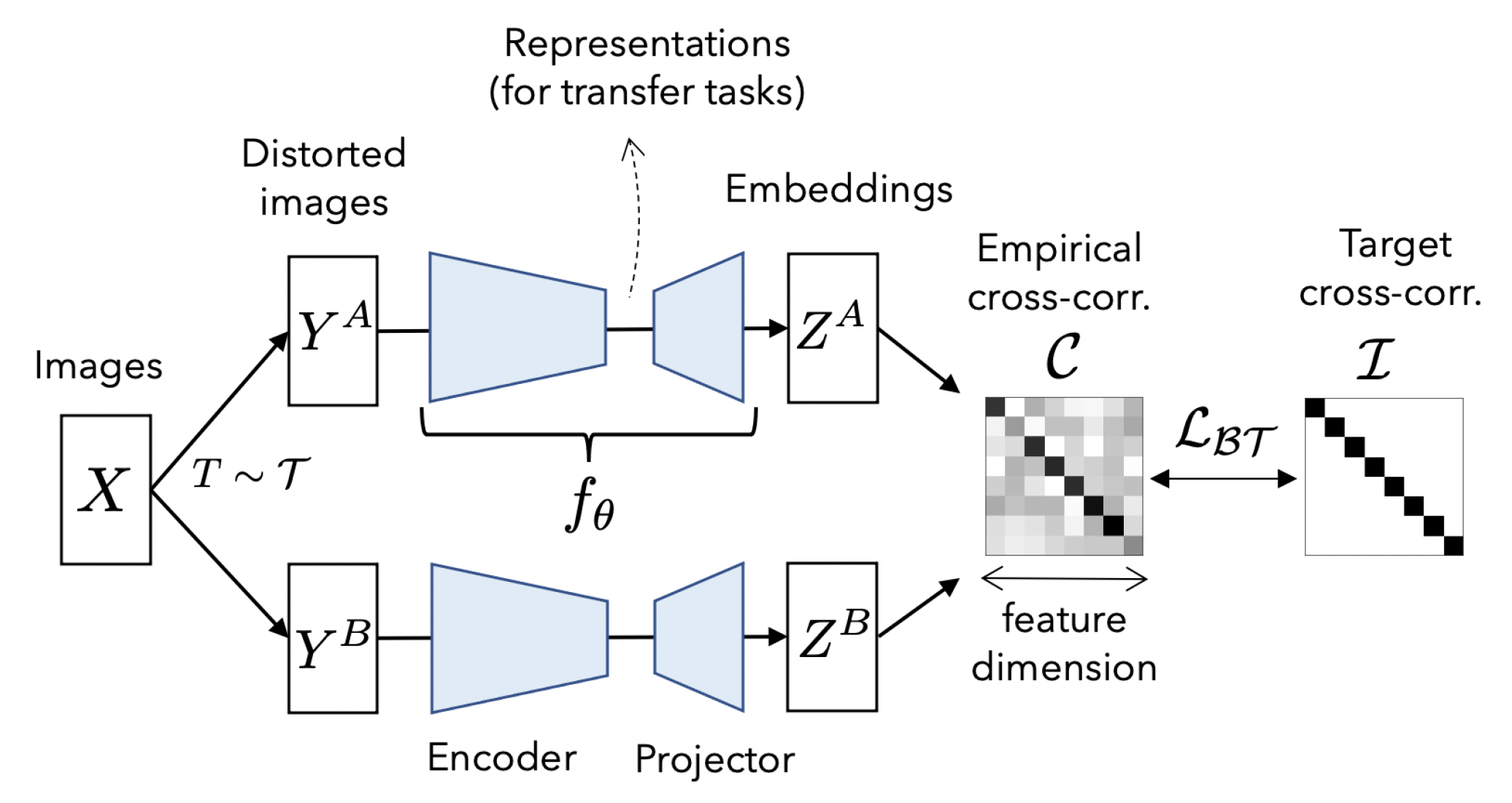
将样本经过不同增广送入同一网络中得到两种表示,利用损失函数迫使它们的互相关矩阵接近于恒等矩阵:这意味着同一样本不同的增广版本下提取出的特征表示非常类似,同时特征向量分量间的冗余最小化。
损失函数如下所示,C为互相关矩阵,其中invariance term使得对角元素接近于1,促使同一样本在不同失真版本下的特征一致性,redundancy reduction term使非对角元素接近0,解耦特征表示的不同向量分量
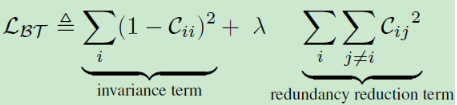
文中还给出了互相关矩阵C的详细计算公式,如下所示: